HyperLake
HyperLake provisions sovereign AI agent infrastructure in your cloud with zero compute markup and governed data access.
Visit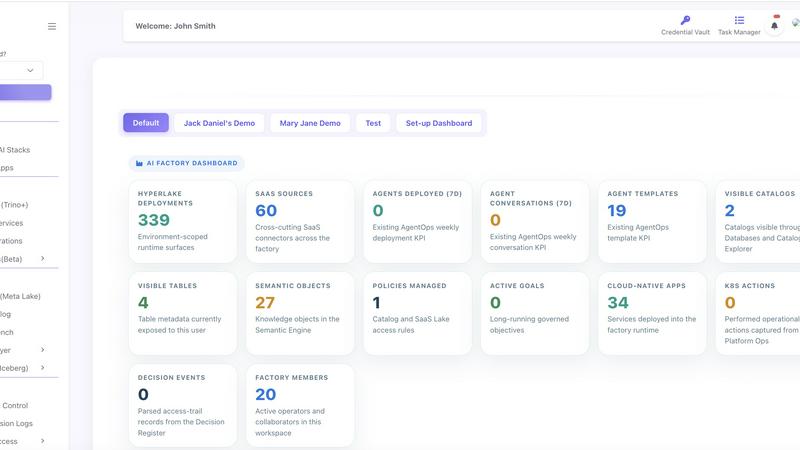
About HyperLake
HyperLake is a sovereign infrastructure platform designed by CerebrixOS for organizations preparing for a world where AI agents become primary consumers of enterprise infrastructure. Traditional enterprise infrastructure was built for humans, dashboards, applications, and scheduled pipelines. AI agents behave fundamentally differently: they query data, call tools, trigger workflows, generate artifacts, operate across multiple systems, and require continuous access to governed compute, data, policies, and services. HyperLake provides the command center to deploy, manage, run, secure, and govern this new agentic infrastructure. The first product wedge is Agentic Data Cloud Infrastructure, which delivers an open-stack data, analytics, semantic, workflow, and agent infrastructure deployed inside the customer's own VPC, private cloud, or on-prem environment. The broader vision extends beyond a single stack: HyperLake is designed to manage many agentic infrastructure stacks, including HyperLake-native stacks, customer-owned cloud services, AWS/GCP/Azure-native components, open-source technologies, governed data services, workflow systems, MCP tools, and future production-ready agentic use cases. The platform offers $0 compute markup, meaning organizations pay only their cloud provider for compute usage, eliminating the financial risk of runaway agent costs. HyperLake is built for enterprises where humans and AI agents operate together on data at scale, providing unified governance, immutable audit trails, data sovereignty by design, and seamless human-agent symbiosis.
Features of HyperLake
Unified Governance and Access Control
HyperLake implements a global policy layer that evaluates every request, whether from a human or an AI agent, against dynamic governance rules in real time. This system enforces Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC), column masking for automatic PII redaction per role, row-level security filtering by department, region, or role, and a complete audit trail with every action version-tracked. Access is enforced consistently across all data sources, queries, and context retrieval operations, ensuring that sensitive information remains protected regardless of the consumer.
The Traceability Loop
Every agent action, inference, query, and training run is recorded through immutable provenance logs. This feature allows organizations to trace any AI decision back to its source data with complete auditability. The traceability loop provides a forensic record of all operations, enabling compliance teams to verify that agents are operating within policy boundaries and data scientists to debug and improve model behavior. This level of observability is critical for regulated industries and enterprises that require strict accountability for AI-driven decisions.
Data Sovereignty by Design
HyperLake enables AI agents to operate on data without moving it outside its secure environment. Sensitive information remains under full owner control through sovereign deployment within the customer's own cloud account, VPC, or on-premises infrastructure. Confidential compute patterns ensure that data processing occurs in trusted execution environments. This architecture eliminates data egress costs and reduces compliance risks, making it ideal for organizations in finance, healthcare, government, and other regulated sectors where data residency is mandatory.
Human-Agent Symbiosis
Humans and AI agents operate on the same governed data platform, sharing standardized context and memory layers. This feature allows human insight and machine intelligence to collaborate on the same datasets without friction. Analysts, data scientists, and engineers work alongside autonomous and supervised agents, all governed by the same policies and accessing the same unified data layer. Shared context enables humans to review, override, or augment agent actions seamlessly, creating a collaborative environment that amplifies both human and machine capabilities.
Use Cases of HyperLake
AI Agent Data Access and Governance
Organizations deploying autonomous AI agents require a governed system of access that prevents unauthorized data exposure while enabling agents to retrieve context, test hypotheses, and iterate continuously. HyperLake provides the policy enforcement layer that evaluates every agent query against RBAC/ABAC rules, column masking policies, and row-level security filters. This use case is critical for enterprises where hundreds of agents operate simultaneously, ensuring that each agent only accesses data appropriate to its role and authorization level.
Autonomous Pipeline Orchestration
AI agents often need to trigger workflows, generate artifacts, and operate across multiple systems in real time. HyperLake enables organizations to deploy agents that can autonomously execute data pipelines, run SQL analytics, generate ML insights, and produce dashboards without human intervention. The platform's governance engine ensures that every pipeline action is auditable and compliant, while the $0 compute markup model allows agents to iterate and retry without financial penalty.
Regulated Industry Compliance and Audit
Financial services, healthcare, and government organizations must maintain strict audit trails for all data access and processing activities. HyperLake's immutable provenance logs record every agent action, inference, query, and training run, providing complete traceability from decision back to source data. This use case enables compliance teams to demonstrate regulatory adherence, investigate anomalies, and generate audit reports with verified, tamper-proof evidence of all agentic operations.
Multi-Cloud and Hybrid Data Federation
Enterprises with data spread across AWS, GCP, Azure, on-premises systems, and SaaS platforms need a unified data layer for AI agents. HyperLake ingests and federates data from OLTP databases (PostgreSQL, MySQL), cloud storage (S3, GCS, Azure, R2), open formats (Iceberg, Delta, Hudi), streaming platforms (Kafka, Kinesis), vector databases (pgVector, Qdrant, Milvus), and over 100 SaaS connectors. Agents can query this federated data without moving it, maintaining data sovereignty while enabling comprehensive AI-driven analysis.
Frequently Asked Questions
What makes HyperLake different from traditional data platforms?
Traditional data platforms were designed for human-centric workflows such as dashboards, reports, and scheduled queries. HyperLake is purpose-built for AI agents that continuously explore, retrieve context, test hypotheses, and iterate. The platform offers $0 compute markup, meaning you pay only your cloud provider for compute usage, eliminating the financial risk of runaway agent costs. Additionally, HyperLake provides a global governance layer that enforces policies consistently across human and agent interactions, with immutable audit trails for complete traceability.
How does HyperLake ensure data sovereignty?
HyperLake is deployed entirely within the customer's own VPC, private cloud, or on-premises environment. Data never leaves the customer's secure infrastructure, and agents operate on data without moving it outside its secure environment. Sensitive information remains under full owner control through sovereign deployment and confidential compute patterns. This architecture eliminates data egress costs, reduces compliance risks, and ensures that organizations maintain complete ownership and control over their data at all times.
Can HyperLake integrate with existing cloud services and tools?
Yes, HyperLake is designed to manage many agentic infrastructure stacks, including HyperLake-native stacks, customer-owned cloud services, AWS/GCP/Azure-native components, open-source technologies, governed data services, workflow systems, and MCP tools. The platform ingests data from over 100 connectors, including OLTP databases, cloud storage, open formats, streaming platforms, and vector databases. This flexibility allows organizations to leverage their existing investments while adding the governance and orchestration layer required for AI agents.
What happens if an AI agent generates excessive queries?
On traditional markup-based platforms, a single misconfigured agent can generate thousands of queries in minutes, leading to unexpected five-figure bills overnight. HyperLake eliminates this risk with its $0 compute markup model. Organizations pay only their cloud provider for the underlying compute resources, regardless of how many queries agents generate. This pricing model gives enterprises the freedom to experiment, iterate, and scale agentic operations without fear of runaway costs, enabling innovation at AI speed.
Similar to HyperLake
Distro is an AI Distribution Operator that helps B2B teams publish content, find buyer conversations, engage prospects, and turn social intent into pi
Polymarket Trading Bot For Crypto
RankOrg automates SEO content creation, researching and publishing optimized articles daily to boost your organic traffic effortlessly.
Skygen AI automates tasks and workflows, empowering businesses to enhance productivity with intelligent AI-driven solutions.
Tuning Engines streamlines AI interactions by providing a unified API for model access, governance, and optimization tailored to your needs.
Minded lets you easily train AI agents to handle tasks autonomously, enhancing team productivity and delivering immediate value.
YCaaS deploys specialized AI agents to cover every role end-to-end, automating entire workflows in one unified system.
xyOps is an all-in-one workflow automation system for orchestrating infrastructure with job scheduling, monitoring, alerting, and ticketing.