diffray vs OpenMark AI
Side-by-side comparison to help you choose the right product.
diffray
Diffray uses AI agents to catch real bugs in your code, not just nitpicks.
Last updated: February 28, 2026
OpenMark AI benchmarks 100+ LLMs on your task: cost, speed, quality & stability. Browser-based; no provider API keys for hosted runs.
Visual Comparison
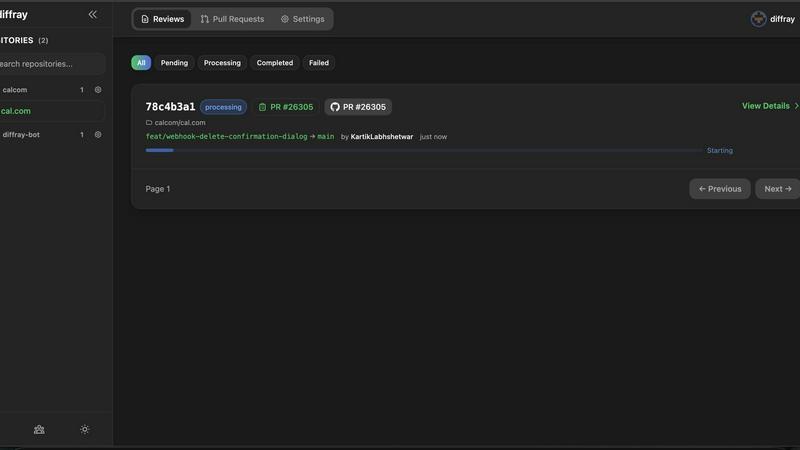
diffray
OpenMark AI

Overview
About diffray
diffray is a next-generation, AI-powered code review platform engineered to solve the core frustrations of modern development teams: noisy, ineffective feedback and missed critical issues. It moves beyond the limitations of traditional single-model AI tools by implementing a sophisticated multi-agent architecture. This system deploys over 30 specialized AI agents, each an expert in a distinct domain such as security vulnerabilities, performance bottlenecks, bug patterns, coding best practices, and even SEO considerations for relevant code. This targeted, domain-specific approach allows diffray to conduct deep, contextual investigations into code changes, replacing generic and speculative suggestions with highly precise, actionable feedback. Crucially, diffray is codebase-aware. It analyzes pull requests and commits within the full context of your repository's existing code, architecture, and historical decisions, ensuring recommendations are relevant and practical. The primary value proposition is a dramatic increase in developer productivity and code quality. diffray aims to reduce the average PR review time from 45 minutes to just 12 minutes per week by filtering out noise and providing trustworthy insights, allowing developers to focus on logic and innovation. It is built for development teams of all sizes who are serious about improving their code security, performance, and maintainability without sacrificing velocity. The platform integrates seamlessly with GitHub, GitLab, and Bitbucket.
About OpenMark AI
OpenMark AI is a web application for task-level LLM benchmarking. You describe what you want to test in plain language, run the same prompts against many models in one session, and compare cost per request, latency, scored quality, and stability across repeat runs, so you see variance, not a single lucky output.
The product is built for developers and product teams who need to choose or validate a model before shipping an AI feature. Hosted benchmarking uses credits, so you do not need to configure separate OpenAI, Anthropic, or Google API keys for every comparison.
You get side-by-side results with real API calls to models, not cached marketing numbers. Use it when you care about cost efficiency (quality relative to what you pay), not just the cheapest token price on a datasheet.
OpenMark AI supports a large catalog of models and focuses on pre-deployment decisions: which model fits this workflow, at what cost, and whether outputs are consistent when you run the same task again. Free and paid plans are available; details are shown in the in-app billing section.