WebPageSnap - Professional Web Scraper API
WebPageSnap is a fast and reliable API that scrapes web pages into JSON or HTML with minimal response time and global.
Visit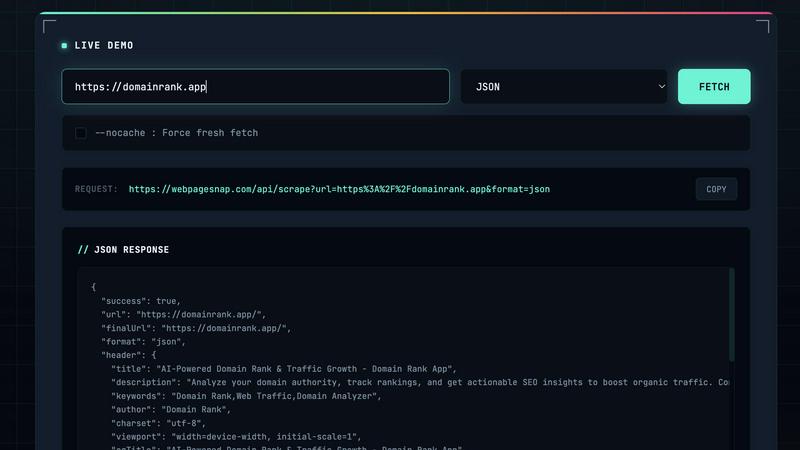
About WebPageSnap - Professional Web Scraper API
WebPageSnap is an advanced web scraping API specifically designed for enterprises, developers, and businesses seeking a reliable tool to extract content from any public webpage efficiently. This service is powered by Cloudflare's robust infrastructure and global CDN, ensuring high-speed access and data retrieval. With an impressive response time of 20-50 ms, WebPageSnap makes it possible to gather data quickly, which is essential for businesses that rely on real-time information. The API intelligently caches web page data with a hit rate of over 95%, significantly reducing unnecessary fetches and conserving API quotas. It automatically extracts crucial metadata, including HTML meta tags, Open Graph data, and Twitter Cards, which are vital for applications in content aggregation, SEO, market research, and data integration. With features like automatic JavaScript redirect handling, CORS readiness for browser use, and a robust free tier, WebPageSnap is ideal for both quick prototyping and scalable production applications.
Features of WebPageSnap - Professional Web Scraper API
Smart Cache
WebPageSnap utilizes a sophisticated caching system with KV storage and a 7-day time-to-live (TTL) for fetched data. This smart cache enhances efficiency by allowing over 95% of requests to be served from cache rather than fetching the live page, thus optimizing API usage and speeding up response times.
Global Edge
The API is deployed across more than 200 edge nodes worldwide, enabling it to deliver responses from the nearest location to the user. This global distribution guarantees low latency and high-speed data retrieval, making it ideal for applications requiring real-time data access.
Multi Format
WebPageSnap supports multiple output formats, allowing users to receive data in either structured JSON or raw HTML. This flexibility caters to different development needs, whether for data processing or direct content integration into applications.
Smart Redirect
The API intelligently handles JavaScript redirects, ensuring that users receive the final content of a webpage, even if it involves navigating through multiple layers of redirection. This feature is particularly beneficial for dynamically generated content and JavaScript-heavy sites.
Use Cases of WebPageSnap - Professional Web Scraper API
Content Aggregation
Developers can leverage WebPageSnap to aggregate content from various sources, enabling the creation of comprehensive databases or news aggregators that pull information from different websites in real-time.
SEO Analysis
Businesses can use the API to extract metadata and analyze website performance. By retrieving key SEO metrics such as page titles, descriptions, and keywords, companies can optimize their own web presence based on competitor insights.
Market Research
WebPageSnap aids in market research by allowing analysts to gather data from numerous websites to study trends, pricing, and product availability, providing valuable insights that inform business strategies.
Data Integration Projects
The API can be utilized in data integration projects where businesses need to feed web data into their systems. By fetching structured data, organizations can seamlessly incorporate external information into their internal databases or applications.
Frequently Asked Questions
What is a web scraper API?
A web scraper API is a tool that enables users to programmatically extract content from websites. WebPageSnap provides structured output in JSON and HTML formats, simplifying the integration of web scraping capabilities into applications.
How does this web scraper API handle JavaScript pages?
WebPageSnap automatically detects and follows JavaScript redirects. By simulating real browser behavior, it ensures users receive the final content of a webpage, even for sites heavily reliant on JavaScript for rendering.
Is the web scraper API free to use?
Yes, WebPageSnap offers a generous free tier, allowing users to make up to 100,000 requests per day. This makes it accessible for developers and businesses to test the API and integrate it into their projects without upfront costs.
What kind of data can I extract with this API?
Users can extract a wide range of data, including standard HTML metadata, Open Graph data, Twitter Cards, and the full HTML content of the webpage. This versatility makes it suitable for various applications, from SEO analysis to content aggregation.
Explore more in this category:
Similar to WebPageSnap - Professional Web Scraper API
AnyApiAI offers a unified API for 400+ AI models, enabling seamless integration and scaling of AI applications without vendor lock-in.
Sorsa API delivers fast, reliable X/Twitter data at 50x lower cost with 20 requests per second and instant setup.
EdgeIQ Labs delivers automated cybersecurity monitoring and scanning for small businesses to identify risks and achieve compliance with clear next.
TrafficClaw is an AI analyst that talks to your live SEO and analytics data to deliver actionable growth insights.
LinkFinder AI instantly enriches your leads with complete company details and contact information.
BlitzAPI provides clean B2B data through powerful APIs to enhance your growth team's go-to-market strategies.
LLMWise offers a single API to access and compare multiple AI models, charging only for usage with no subscriptions.
AntiTemp is an email verification API that enhances product growth and risk management through actionable intelligence.