Friendli Engine
About Friendli Engine
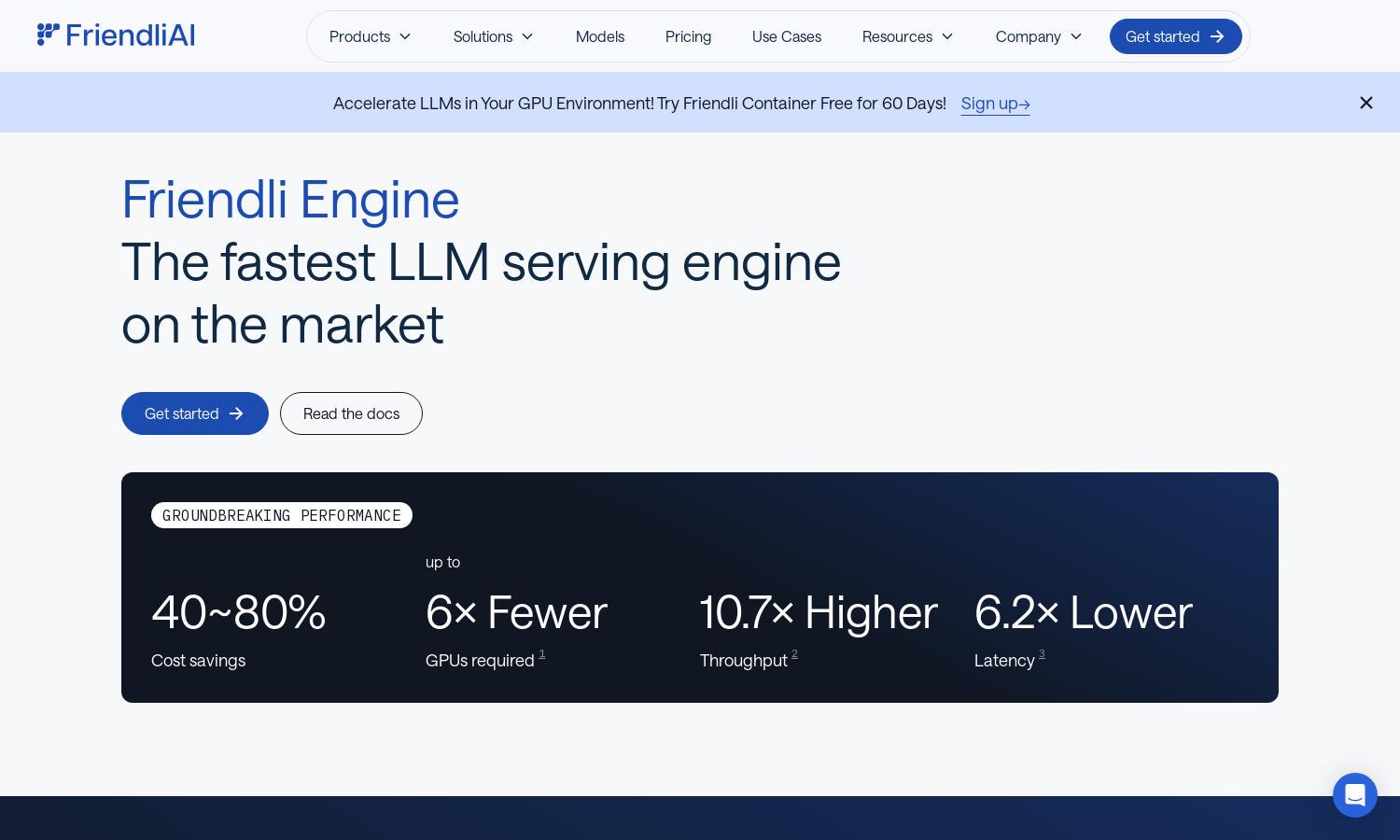
Friendli Engine offers an innovative platform for fast and cost-effective LLM inference, targeting developers and businesses seeking efficient AI model deployment. Its patented iteration batching technology enhances performance by handling multiple requests simultaneously, providing significant cost savings and a seamless experience for users looking to harness generative AI.
Friendli Engine offers flexible pricing plans tailored for different user needs. Each tier provides unique benefits, including optimized GPU usage, access to advanced features, and significant cost reductions. Users can explore trial options to experience improved performance and evaluate the advantages of upgrading for additional functionality.
Friendli Engine features an intuitive interface designed for ease of use, allowing users to quickly access and utilize LLM models. The layout supports clear navigation through its functionalities, ensuring a seamless experience. With dedicated endpoints and container options, users can efficiently manage AI model deployment.
How Friendli Engine works
Users interact with Friendli Engine by signing up and selecting their desired service plan. After onboarding, they can easily navigate the user-friendly dashboard to choose from various generative AI models. The platform's unique iteration batching and caching technologies optimize LLM inference, significantly reducing costs and enhancing performance, providing a robust environment for AI development.
Key Features for Friendli Engine
Multi-LoRA Support
Friendli Engine's Multi-LoRA support enables concurrent running of multiple LoRA models on a single GPU, significantly enhancing efficiency. This feature allows users to customize and deploy LLMs more effectively and cost-efficiently, providing greater flexibility and resource optimization for generative AI applications.
Iteration Batching
Iteration batching is a cutting-edge technology of Friendli Engine that boosts LLM inference throughput by managing multiple requests simultaneously. This unique approach results in higher efficiency and lower latency, ensuring user satisfaction with rapid response times while maintaining cost-effectiveness in AI deployments.
Friendli TCache
Friendli TCache intelligently identifies and saves frequently accessed computational results, substantially reducing GPU workload. By utilizing cached data, Friendli Engine offers faster time-to-first-token responses, making it a valuable asset for developers seeking swift and efficient LLM inference for their generative AI models.








